
Crawl4AI是什么
Crawl4AI是一个开源的Web数据抓取工具,专为需要采集大规模数据以支持AI研究和应用的人群设计。该项目主要是用Python编写,能够从指定的网站提取多种形式的数据,包括文本、图像、以及结构化数据。其目的是帮助用户高效地从互联网收集数据,并以结构化的格式输出,以便后续的数据分析和机器学习用途。
Crawl4AI截图展示
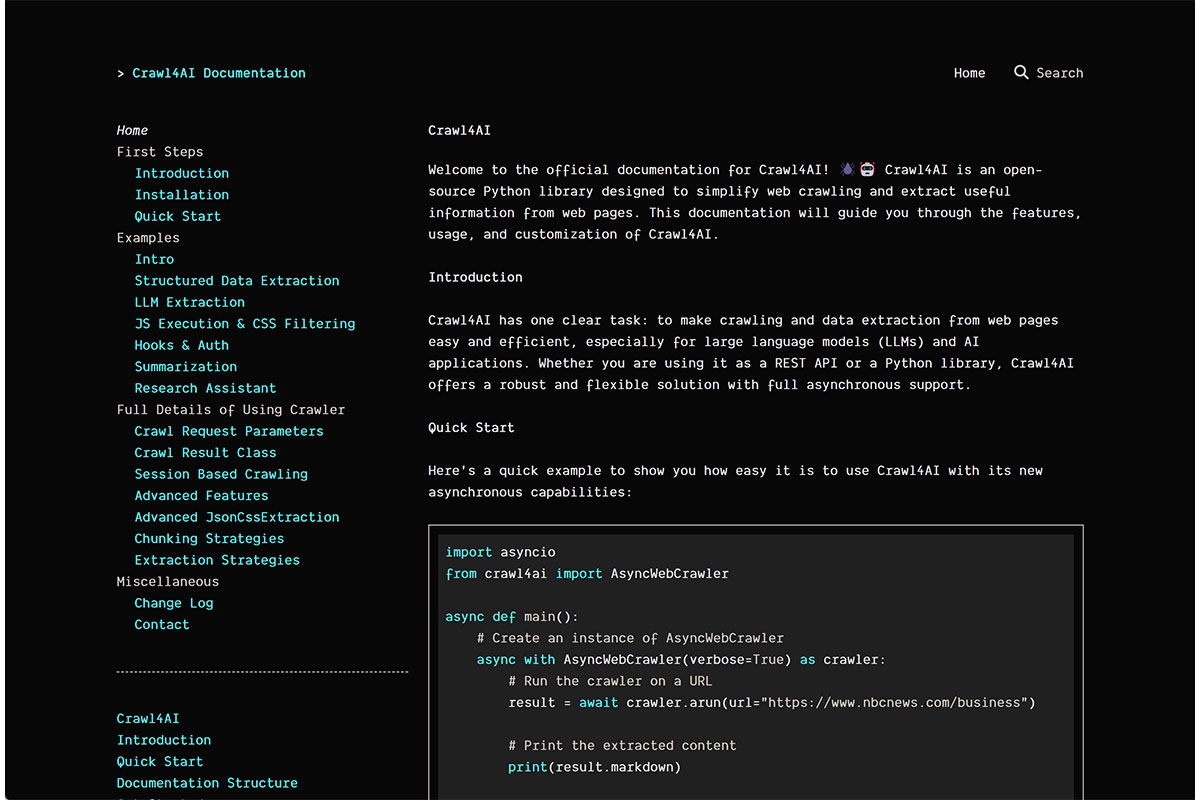
Crawl4AI主要功能
- 灵活的数据提取:支持XPATH、CSS等多种选择器语法,用户可以灵活地从复杂的网页结构中抓取数据。
- 并行抓取:基于多线程和异步I/O技术,Crawl4AI可以同时处理多个请求,大幅提升数据抓取的速度。
- 数据存储:抓取的数据可以自动存储为CSV、JSON等多种文件格式,便于数据管理和后续分析。
- 用户定义的解析规则:用户可以根据具体需求定义抓取规则,以保证数据的准确性和完整性。
- 防封禁机制:内置多种策略,如设置抓取间隔、模拟浏览器请求,以规避网站的抓取限制。
Crawl4AI官网
https://github.com/unclecode/crawl4ai
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。